Magandang hapon
Marahil, ang bawat isa sa atin ay nahaharap sa gawain kung kinakailangan upang isalin ang isang dokumento sa papel sa electronic form. Ito ay lalong kinakailangan lalo na para sa mga nag-aaral, gumana sa dokumentasyon, isalin ang mga teksto gamit ang mga electronic dictionaries, atbp
Sa artikulong ito, nais kong ibahagi ang ilan sa mga pangunahing kaalaman sa prosesong ito. Sa pangkalahatan, ang pag-scan at pagkilala sa teksto ay medyo oras, dahil ang karamihan sa mga operasyon ay kailangang gawin nang manu-mano. Susubukan naming malaman kung ano, paano, at bakit.
Hindi lahat ay agad na naiintindihan ang isang bagay. Matapos ang pag-scan (umaangkop sa lahat ng mga sheet sa scanner) magkakaroon ka ng mga larawan sa BMP, JPG, PNG, GIF format (maaaring mayroong iba pang mga format). Kaya, mula sa larawang ito kailangan mong makuha ang teksto - ang pamamaraang ito ay tinatawag na pagkilala. Sa pagkakasunud-sunod na ito ay magiging pahayag sa ibaba.
Mga nilalaman
- 1. Ano ang kinakailangan para sa pag-scan at pagkilala?
- 2. Mga pagpipilian sa pag-scan ng teksto
- 3. Pagkilala sa teksto ng dokumento
- 3.1 Teksto
- 3.2 Mga Larawan
- 3.3 Mga Talahanayan
- 3.4 Hindi kinakailangang mga item
- 4. Pagkilala ng mga file na PDF / DJVU
- 5. Sinusuri ang mga error at pag-save ng mga resulta ng trabaho
1. Ano ang kinakailangan para sa pag-scan at pagkilala?
1) Scanner
Upang ma-convert ang mga nakalimbag na dokumento upang mag-text, kailangan mo muna ng isang scanner at, nang naaayon, ang "katutubong" mga programa at mga driver na sumama dito. Gamit ang mga ito, maaari mong mai-scan ang isang dokumento at i-save ito para sa karagdagang pagproseso.
Maaari kang gumamit ng iba pang mga analogue, ngunit ang software na dumating kasama ang scanner sa kit ay karaniwang gumagana nang mas mabilis at may maraming mga pagpipilian.
Depende sa kung anong uri ng scanner ang mayroon ka, ang bilis ng trabaho ay maaaring magkakaiba nang malaki. May mga scanner na maaaring makatanggap ng larawan mula sa isang sheet sa loob ng 10 segundo, mayroong matatanggap sa loob ng 30 segundo. Kung nag-scan ka ng isang libro para sa 200-300 sheet - sa palagay ko hindi mahirap kalkulahin kung ilang beses na magkakaroon ng pagkakaiba sa oras?
2) programa ng pagkilala
Sa aming artikulo ipapakita ko sa iyo ang gawain sa isa sa mga pinakamahusay na programa para sa pag-scan at pagkilala ng ganap na anumang mga dokumento - ABBYY FineReader. Dahil Dahil nabayaran ang programa, magbibigay agad ako ng isang link sa isa pa - ang libreng analogue ng Cunei Form. Totoo, hindi ko ihahambing ang mga ito, dahil sa ang katunayan na ang FineReader ay nanalo sa lahat ng aspeto, inirerekumenda ko pa ring subukan ito.

ABBYY FineReader 11
Opisyal na website: //www.abbyy.ru/
Isa sa mga pinakamahusay na programa ng uri nito. Ito ay idinisenyo upang makilala ang teksto sa larawan. Itinayo-sa maraming mga pagpipilian at pag-andar. Maaari itong mag-parse ng isang grupo ng mga font, sinusuportahan din nito ang mga pagpipilian sa sulat-kamay (kahit na hindi ko ito personal na sinubukan, sa palagay ko ay hindi malamang na makikilala ang bersyon ng sulat-kamay, maliban kung mayroon kang perpektong sulat-kamay ng kaligrapya). Ang higit pang mga detalye tungkol sa pagtatrabaho dito ay ilalarawan sa ibaba. Narito din namin tandaan na ang artikulo ay pag-uusapan tungkol sa pagtatrabaho sa bersyon 11 na programa.
Bilang isang patakaran, ang iba't ibang mga bersyon ng ABBYY FineReader ay hindi naiiba sa bawat isa. Madali mong magawa ang pareho sa isa pa. Ang pangunahing pagkakaiba ay maaaring sa kaginhawaan, bilis ng programa at mga kakayahan nito. Halimbawa, ang mga naunang bersyon ay tumangging magbukas ng isang PDF at DJVU ...
3) Mga dokumento para sa pag-scan
Oo, tulad nito, nagpasya akong gawin ang mga dokumento na isang hiwalay na haligi. Sa karamihan ng mga kaso, ang ilang mga aklat-aralin, pahayagan, artikulo, magasin, atbp, ay na-scan. mga librong iyon at panitikan na hinihiling. Ano ang pinangungunahan ko? Mula sa personal na karanasan, masasabi kong marami na nais mong i-scan ay marahil ay nasa network na! Ilang beses ko na personal na nai-save ang oras nang may nakita akong isang partikular na libro na na-scan sa network. Ang kailangan ko lang gawin ay kopyahin ang teksto sa dokumento at magpatuloy sa paggawa nito.
Mula dito, isang simpleng tip - bago ka mag-scan ng isang bagay, suriin kung may na-scan na at may hindi ka kailangang pag-aaksaya ng iyong oras.
2. Mga pagpipilian sa pag-scan ng teksto
Dito hindi ko sasabihin ang tungkol sa iyong mga driver para sa scanner, mga programa na sumama dito, dahil ang lahat ng mga modelo ng mga scanner ay magkakaiba, iba rin ang software sa lahat ng dako, at hindi makatotohanang hulaan kung paano gaganap ang operasyon.
Ngunit ang lahat ng mga scanner ay may parehong mga setting, na maaaring makaapekto sa bilis at kalidad ng iyong trabaho. Tatalakayin lang natin sila dito. Maglista ako ng maayos.
1) kalidad ng pag-scan - DPI
Una, itakda ang kalidad ng pag-scan sa mga pagpipilian sa hindi bababa sa 300 DPI. Maipapayo kahit na magtakda ng higit kung posible. Ang mas mataas na tagapagpahiwatig ng DPI, mas malinaw ang iyong larawan, at sa gayon, ang karagdagang pagproseso ay magiging mas mabilis. Bilang karagdagan, mas mataas ang kalidad ng pag-scan, mas kaunting mga error na kakailanganin mong iwasto sa ibang pagkakataon.
Ang pinakamahusay na pagpipilian ay karaniwang nagbibigay ng 300-400 DPI.
2) Kulay
Ang parameter na ito ay nakakaapekto sa oras ng pag-scan nang napakalakas (sa pamamagitan ng paraan, nakakaapekto rin ang DPI, ngunit ang mga ito ay napakalakas, at lamang kapag ang gumagamit ay nagtatakda ng mataas na halaga)
Karaniwan mayroong tatlong mga mode:
- itim at puti (perpekto para sa payak na teksto);
- kulay abo (angkop para sa teksto na may mga talahanayan at larawan);
- kulay (para sa mga magazine ng kulay, libro, sa pangkalahatan, mga dokumento kung saan mahalaga ang kulay).
Karaniwan, ang oras ng pag-scan ay nakasalalay sa pagpili ng kulay. Sa katunayan, kung mayroon kang isang malaking dokumento, kung gayon kahit ang labis na 5-10 segundo sa pahina bilang isang kabuuan ay ibubuhos sa isang disenteng oras ...
3) Mga Larawan
Maaari kang makakuha ng isang dokumento hindi lamang sa pamamagitan ng pag-scan, kundi pati na rin sa pamamagitan ng pagkuha ng litrato. Bilang isang patakaran, sa kasong ito magkakaroon ka ng iba pang mga problema: pagbaluktot ng larawan, lumabo. Dahil dito, maaaring kailanganin ang isang mas mahabang karagdagang pag-edit at pagproseso ng natanggap na teksto. Personal, hindi ko inirerekumenda ang paggamit ng mga camera para sa negosyong ito.
Mahalagang tandaan na hindi lahat ng nasabing dokumento ay maaaring makilala, sapagkat ang kalidad ng pag-scan ay maaaring napakababa ...
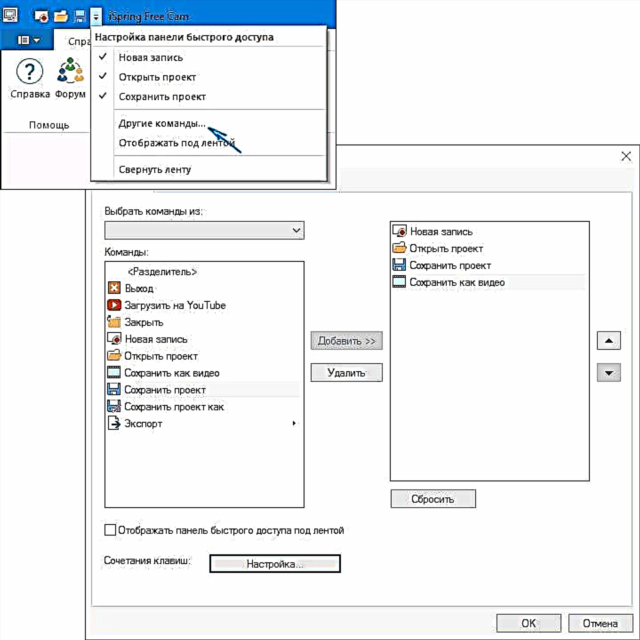
3. Pagkilala sa teksto ng dokumento
Ipinapalagay namin na natanggap mo ang itinakdang mga na-scan na mga pahina. Kadalasan ang mga ito ay mga format: tif, bmb, jpg, png. Sa pangkalahatan, para sa ABBYY FineReader - hindi ito napakahalaga ...
Matapos mabuksan ang isang larawan sa ABBYY FineReader, ang programa, bilang isang panuntunan, awtomatikong pumili ng mga lugar at kinikilala ang mga ito sa makina. Ngunit kung minsan ginagawa niya itong mali. Para sa mga ito, isasaalang-alang namin nang manu-mano ang pagpili ng mga kinakailangang lugar.
Mahalaga! Hindi lahat ay agad na naiintindihan na pagkatapos ng pagbukas ng isang dokumento sa programa, ang pinagmulan ng dokumento ay ipinapakita sa kaliwang window, kung saan pipili ka ng iba't ibang mga lugar. Matapos ang pag-click sa pindutan ng "pagkilala", ang programa sa window sa kanan ay magpapakita sa iyo ng tapos na teksto. Matapos ang pagkilala, sa pamamagitan ng paraan, ipinapayong suriin ang teksto para sa mga pagkakamali sa parehong FineReader.
3.1 Teksto
Ginagamit ang lugar na ito upang i-highlight ang teksto. Ang mga larawan at talahanayan ay dapat na maibukod dito. Bihira at hindi pangkaraniwang mga font ay kailangang maipasok nang manu-mano ...
Upang pumili ng isang lugar ng teksto, bigyang pansin ang panel sa tuktok ng FineReader. May isang pindutan na "T" (tingnan ang screenshot sa ibaba, ang pointer ng mouse ay nasa butones na ito). Mag-click dito, pagkatapos ay sa imahe sa ibaba, piliin ang maayos na hugis-parihaba na lugar kung saan matatagpuan ang teksto. Sa pamamagitan ng paraan, sa ilang mga kaso kailangan mong lumikha ng mga bloke ng teksto ng 2-3, at kung minsan ay 10-12 bawat pahina, dahil maaaring maiiba ang pag-format ng teksto at ang isang rektanggulo ay hindi pumili ng buong lugar.
Mahalagang tandaan na ang mga imahe ay hindi dapat mahulog sa lugar ng teksto! Sa hinaharap, ito ay magse-save ka ng maraming oras ...

3.2 Mga Larawan
Ginamit upang i-highlight ang mga imahe at lugar na mahirap makilala dahil sa hindi magandang kalidad o hindi pangkaraniwang font.
Sa screenshot sa ibaba, ang pointer ng mouse ay matatagpuan sa pindutan na ginamit upang piliin ang lugar na "larawan". Sa pamamagitan ng paraan, maaari mong piliin ang ganap na anumang bahagi ng pahina, at pagkatapos ay ipinasok ito ng FineReader sa dokumento bilang isang normal na larawan. I.e. "tanga" lang ang kopya ...
Karaniwan ang lugar na ito ay ginagamit upang i-highlight ang hindi magandang mga naka-scan na mga talahanayan, upang i-highlight ang hindi pamantayang teksto at font, sa pamamagitan ng mga larawan mismo.

3.3 Mga Talahanayan
Ang screenshot sa ibaba ay nagpapakita ng isang pindutan para sa pag-highlight ng mga talahanayan. Sa pangkalahatan, personal kong ginagamit ito nang labis. Ang katotohanan ay kakailanganin mong sa halip ay regular na gumuhit (sa katunayan) ang bawat linya sa mesa at ipakita kung ano at paano sa programa. Kung ang talahanayan ay maliit at sa hindi napakahusay na kalidad, inirerekumenda ko ang paggamit ng lugar na "larawan" para sa mga layuning ito. Kaya, makatipid ng maraming oras, at ang mesa ay maaaring mabilis na magawa sa Salita batay sa larawan.

3.4 Hindi kinakailangang mga item
Mahalagang tandaan. Minsan walang mga kinakailangang elemento sa pahina na makagambala sa pagkilala sa teksto, o kahit na pigilan ka mula sa pag-highlight ng nais na lugar. Maaari silang matanggal gamit ang pambura.
Upang gawin ito, pumunta sa mode ng pag-edit ng imahe.

Piliin ang pambura na tool at piliin ang hindi kinakailangang lugar. Tatanggalin ito at ang isang puting sheet ng papel ay nasa lugar nito.

Sa pamamagitan ng paraan, inirerekumenda ko na gamitin mo ang pagpipiliang ito hangga't maaari. Subukan ang lahat ng mga lugar na teksto na iyong napili, kung saan hindi mo na kailangan ang isang piraso ng teksto, o anumang mga hindi kinakailangang tuldok, blurring, distortions ay naroroon - tanggalin sa isang pambubura. Salamat sa ito, ang pagkilala ay magiging mas mabilis!
4. Pagkilala ng mga file na PDF / DJVU
Sa pangkalahatan, ang format na ito ng pagkilala ay hindi naiiba sa iba pa - i.e. maaari kang magtrabaho kasama nito tulad ng mga larawan. Ang tanging bagay ay ang programa ay hindi dapat maging masyadong luma kung ang mga PDF / DJVU file ay hindi magbubukas para sa iyo - mag-upgrade sa bersyon 11.
Isang maliit na tip. Matapos buksan ang dokumento sa FineReader - awtomatiko itong magsisimulang kilalanin ang dokumento. Kadalasan sa mga file na PDF / DJVU, hindi kinakailangan ang isang tiyak na lugar ng pahina sa buong dokumento! Upang alisin ang nasabing lugar sa lahat ng mga pahina, gawin ang mga sumusunod:
1. Pumunta sa seksyon ng pag-edit ng imahe.
2. I-on ang pagpipilian na "crop".
3. Piliin ang lugar na gusto mo sa lahat ng mga pahina.
4. Mag-click mag-apply sa lahat ng mga pahina at pag-crop.

5. Sinusuri ang mga error at pag-save ng mga resulta ng trabaho
Tila maaaring magkaroon pa rin ng mga problema kapag ang lahat ng mga lugar ay na-highlight, pagkatapos ay kinikilala - dalhin ito at i-save ... Narito ito!
Una, kailangan mo ng isang pagsusuri sa dokumento!
Upang paganahin ito, pagkatapos ng pagkilala, sa window sa kanan, magkakaroon ng isang "check" na pindutan, tingnan ang screenshot sa ibaba. Matapos ang pag-click nito, ang programang FineReader ay awtomatikong magpapakita sa iyo ng mga lugar kung saan ang mga programa ay may mga pagkakamali at hindi ito mapagkakatiwalaang makilala ang isang partikular na karakter. Kailangan mo lamang pumili, sumasang-ayon ka man sa opinyon ng programa, o ipasok ang iyong pagkatao.
Sa pamamagitan ng paraan, sa kalahati ng mga kaso, humigit-kumulang, ang programa ay mag-aalok sa iyo ng isang handa na tamang salita - kailangan mong piliin ang kinakailangang pagpipilian gamit ang mouse.
Pangalawa, pagkatapos suriin, kailangan mong piliin ang format kung saan nai-save mo ang resulta ng iyong trabaho.
Dito pinapayagan ka ng FineReader na umikot sa pinakadulo: maaari mo lamang ilipat ang impormasyon sa Salita ng isa sa isa, o mai-save mo ito sa isa sa dose-dosenang mga format. Ngunit nais kong i-highlight ang isa pang mahalagang aspeto. Anuman ang format na pinili mo, mas mahalaga na piliin ang uri ng kopya! Isaalang-alang ang mga pinaka-kagiliw-giliw na mga pagpipilian ...

Eksaktong kopya
Ang lahat ng mga lugar na iyong na-highlight sa pahina sa kinikilalang dokumento ay tutugma mismo sa orihinal na dokumento. Ang isang napaka-maginhawang pagpipilian kapag mahalaga para sa iyo na hindi mawala ang pag-format ng teksto. Sa pamamagitan ng paraan, ang mga font ay magiging katulad din sa orihinal. Sa pagpipiliang ito, inirerekumenda kong ilipat ang dokumento sa Salita upang ang karagdagang trabaho ay maaaring magpatuloy doon.
Nai-edit na Kopya
Magaling ang pagpipiliang ito na nakakuha ka na ng na-format na bersyon ng teksto. I.e. indisyon na may "kilometrong", na maaaring nasa dokumento ng mapagkukunan - hindi ka makakamit. Kapaki-pakinabang na pagpipilian kapag ikaw ay makabuluhang i-edit ang impormasyon.
Totoo, hindi ka dapat pumili kung mahalaga para sa iyo na mapanatili ang estilo ng disenyo, mga font, mga indent. Minsan, kung ang pagkilala ay hindi masyadong matagumpay, ang iyong dokumento ay maaaring "skew" dahil sa nabago na pag-format. Sa kasong ito, ipinapayong pumili ng eksaktong kopya.
Plain ng teksto
Isang pagpipilian para sa mga nangangailangan lamang ng teksto mula sa isang pahina nang wala ang lahat. Angkop para sa mga dokumento na walang mga larawan at mga talahanayan.
Sa artikulong ito sa pag-scan at pagkilala sa isang dokumento ay natapos. Inaasahan ko na sa mga simpleng tip na ito ay malulutas mo ang iyong mga problema ...
Buti na lang